![[인물탐구] 18년 야인에서 ‘권력의 참모장’으로···김민석 총리의 생환 서사](/news/thumbnail/202507/66679_76621_484_v150.jpg)



[인더스트리뉴스 최종윤 기자] 한국전자기술연구원(KETI, 원장 김영삼)은 최첨단 언어처리 모델 ‘KE-T5‘를 공개했다. KE-T5는 구글의 언어모델 알고리즘인 T5를 기반으로 구축한, 한국어와 영어처리에 모두 활용 가능한 자기지도학습 방식의 이중 언어처리 모델이다.
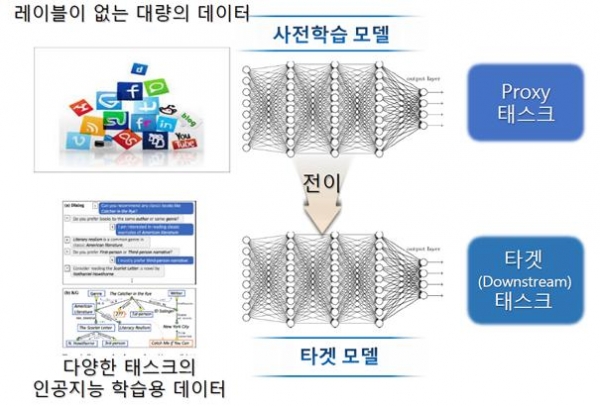
KE-T5는 최초의 한국어 데이터 중심 T5계열 모델이자, 언어의 의미 인식 특성과 표현 특성을 모두 포함하고 있는 범용 언어모델이다. 인공지능 소수학습(Few-shot learning)을 지원해, 소수의 학습데이터만으로 다양한 언어처리에서 높은 성능을 보이기에 구축비용 대비 높은 활용성을 자랑한다.
한국어와 영어의 동시 처리가 가능하며, 기존 모델에서 상대적으로 저조했던 문서 요약, 영-한 및 한-영 번역, 대화 등의 언어이해는 물론 표현의 연계학습이 필요한 고난도의 언어처리에서도 우수한 결과를 보인다.
KETI는 텍스트의 종류와 학습 규모에 따라 16종의 모델을 무상으로 배포해, 개발자가 개발환경과 엔진 특성에 따라 선택해 활용할 수 있도록 했다. 또 바로 활용 가능한 24종의 한국어-영어 요약, 번역 모델들도 함께 공개했다. 이 언어모델들은 Apache 2.0 라이선스에 따라 자유롭게 사용 및 배포가 가능하기에 국내에서 다양한 언어처리 분야에 활용될 것으로 기대된다.
이번 연구를 주도한 인공지능연구센터 신사임 센터장은 “영어 중심의 사전학습 언어처리 기술은 그동안 높은 구축비용으로 기업들에게 부담을 줬다”면서, “KE-T5의 규모를 계속해서 대형화 하고 있는 바 결과물들을 지속적으로 공개해 원천 언어처리기술 분야의 발전과 사업화 지원을 위해 앞장서겠다”고 포부를 밝혔다.
한편, 이번 기술은 과기부와 IITP, NIPA 지원의 ‘자기지도 학습에 의한 시각적 상식으로 영상에서 보이지 않는 부분을 복원하는 기술’, ‘정서적 안정을 위한 인공지능 기반 공감서비스 기술 개발’, ‘비정형 텍스트를 학습해 쟁점별 사실과 논리적 근거추론이 가능한 인공지능 원천기술’ 과제를 통해 개발됐다.

![이재명 대통령 지지율 65%...전 지역·전 연령대 과반 지지 [한국갤럽]](/news/thumbnail/202507/66675_76616_2228_v150.jpg)




